
Webスクレイピングも、ある程度のレベルに達すると次の壁に当たります。

他のページにある情報も一緒にスクレイピングしたい…。
過去ページに埋もれた情報を基本的な技術でまとめて取得するのは難しいです。
そこで今回は、自動で(次のページ)ボタンを押してくれるツールを使って、webサイトの全情報をスクレイピング出来る方法を紹介します。
Robobrowserを使う
PythonではWebスクレイピングする時、requestやBeautifulSoupライブラリを使うことが多いですが、基本的に一つのページしか取得できません。
しかし、robobrowserを使えば他のページに飛ぶことが出来ます。
さらにスゴいことに、robobrowserの内部ではBeautifulSupが動いているため、ゼロから仕様を覚える必要がなく、BeautifulSoupを動かしている感覚でコードを書くことが出来るのです。
ブログ内の全記事を取得してみよう
さっそくプログラムを組んでいきましょう。
今回は「しれっと更新ブログ」にある104記事(2019年4月時点)のタイトルとURLを取得してみましょう。
先にコードを紹介します。
import time
from robobrowser import RoboBrowser
# parserを指定、この形からもrobobrowserがBeautifulSoupを基に動いていることが分かる。
browser = RoboBrowser(parser="html.parser")
def main():
browser.open("https://barniclebattleline.com/") # しれっと更新ブログ
while True:
# 今いるページの記事のタイトル&リンクを取得する関数
print_all_articles()
# "次のページ"というテキストを持つリンク取得
link_to_next = browser.get_link("次のページ")
if not link_to_next:
# "次のページ"のリンクがない場合ループを抜けて終了
break
# "次のページ"に飛ぶ
browser.follow_link(link_to_next)
# 現在のページの全記事&リンク表示
def print_all_articles():
names = browser.select("h2")
links = browser.select(".entry-card-wrap")
# 現在のページの全記事タイトル&リンク取得
for i in range(len(names)):
print(names[i].text, links[i].get("href")) # 記事のタイトル&リンク表示
time.sleep(1)
if __name__ == "__main__":
main()
基本的な仕組みは、parser機能と(次へ)ボタンを押す機能を持ったmain関数の中に、現在のページの記事タイトルとリンクをfor文を使って取得するprint_all_articles関数を入れて動かすという感じです。
browser変数にhtml.parserを伝えていることからも、robobrowserがBeautifulSoupで動いているということが分かりますね。
また、相手のサーバーに負担をかけないためにtimeで1秒の間隔を空けています。
robobrowserのスゴいところは、browser.get_linkで特定の文字列が書かれているボタンを押すことが出来るということです。
つまり、(次のページ)や(前のページ)ボタンに限らず、カテゴリー、アーカイブなどのリンクに飛ぶことも出来るのです。
そして実行結果がコレ、
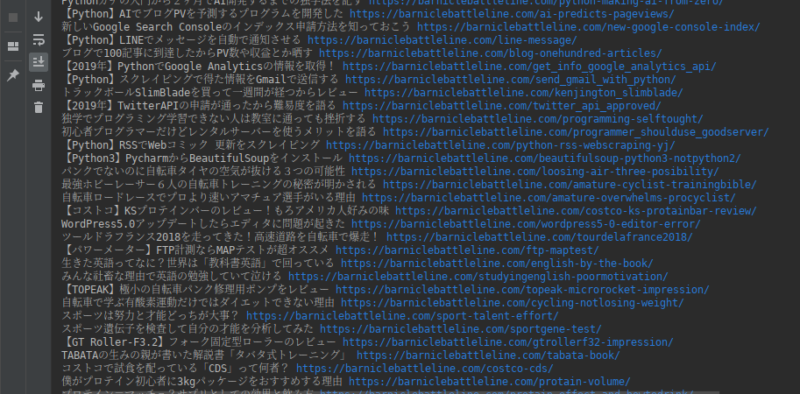
print_all_articles関数のfor文をもう一つ追加すれば、記事のリンクに飛んで本文をスクレイピングすることも可能です。
このテクニックを応用すれば、通販サイトでスクレイピングした商品の価格といった情報を、カテゴリーやページに関係なく一発で取得して、csv形式などで保存することも出来ます。
実際にクラウドワークスではこういう案件を数万円単位で依頼していることもザラです。
まとめ
以上、他のページにまたがっているWeb情報をスクレイピングする方法の紹介でした。
この方法は工夫すれば何百という情報を短時間で取得できる代わりに、相手側のサーバーに負担を掛けることがあります。運営側に迷惑をかけないためにも、できるだけtimeなどを使って間隔を空けてリクエストしましょう。

