Pythonが注目される理由の一つに「人工知能・機械学習の開発に向いているから」ということが挙げられます。それほど懇切丁寧にライブラリ&説明が豊富にあるのです。
今回はブログPVの予測プログラムの紹介して、プログラミング初心者でもAI開発が可能だということを語っていきます。
ステップ1:Google Analytics からデータを収集
まずは機械学習に使うデータを収集します。今回はブログのPVが必要なので、普段使っているGoogle Analyrics からCSVレポートを取得します。
Google Analytics にログインしてユーザーサマリーに進み、右上にある【エクスポート】をクリック、そしてcsv形式を選び、コードを書くディレクトリに置いて下さい。
期間はブログを始めた日から昨日までを指定します。ファイルの名前はanalytics.csvとしましょう。
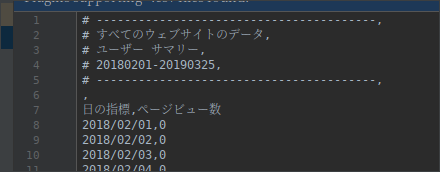
メモ帳やIDEで開くと、下図のような見出しとともにズラーッと日にちとPVが記されていると思います。
ステップ2:データを加工する
以上で必要なデータは揃いました。しかし、このままではデータを読み込むのに不便なのでデータを加工します。
具体的にはテキストにある見出しを全て消して“日にち,PV”という新しい見出しを付けて、日付をスラッシュ抜きに(例えば 2018/10/01 なら 20181001 のように)します。
以下がそれを行うコードです。
# csvファイルを読み込む
with open(analytics.csv, "rt", encoding="utf-8") as fr:
lines = fr.readlines()
# ヘッダーを消して新しいヘッダーをつける
lines = ["日にち,ユーザー,PV\n"] + lines[7:]
lines = map(lambda v: v.replace("/", ""), lines)
result = "".join(lines).strip()
print(result)
# 結果をファイルへ
with open(analytics_new, "wt", encoding="utf-8") as fw:
fw.write(result)
print("saved.")
新しいファイルの名前はanalytics_new.csvとします。これでcsvファイルが理想の形になりました、次はいよいよメインプログラムを組んでいきます。
ステップ3:コードを書く
「説明は要らない、実際に触って理解する」という方のために先に全コードを紹介します。
from sklearn.linear_model import LinearRegression
import pandas as pd
import matplotlib.pyplot as plt
# analytics読み込み
df = pd.read_csv("analytics_new.csv", encoding="utf-8")
# 学習用とテスト用に分割
train_year = (df["日にち"] <= 20181231)
test_year = (df["日にち"] >= 20190101)
interval = 6
# 過去6日分を学習するデータ作成
def make_data(data):
x = [] # 学習データ
y = [] # 結果
temps = list(data["PV"])
for i in range(len(temps)):
if i < interval:
continue
y.append(temps[i])
xa = []
for p in range(interval):
d = i + p - interval
xa.append(temps[d])
x.append(xa)
return x, y
train_x, train_y = make_data(df[train_year])
test_x, test_y = make_data(df[test_year])
# 回帰分析
lr = LinearRegression(normalize=True)
lr.fit(train_x, train_y) # 学習
pre_y = lr.predict(test_x) # 予測
# 図に表示
plt.figure(figsize=(10, 6), dpi=100)
plt.plot(test_y, c="r")
plt.plot(pre_y, c="b")
plt.savefig("pv_predictor.png")
plt.show()
# 平均誤差と最大誤差
diff_y = abs(pre_y - test_y)
print("average=", sum(diff_y) / len(diff_y))
print("max=", max(diff_y))
sklearn, pandas, matplotlibの3つをインポートした後、pandasを使って先ほど作成したanalytics_new.csvを読み込みます。
つぎに日にちを指定してデータを学習用とテスト用に分割します。学習用のデータでPVの変動パターンを覚え込ませ、テスト用はそれを踏まえてPVを予測するために使います。経験上おおよそ8:2が精度が良い気がします。
分割が済んだら、今度は7日分のデータを作成します。PVを予測するにあたりプログラムは直近7日分のデータをもとに翌日のPVを推測します。「7日間のデータで1日を予測」を繰り返して指定したデータの日にち全てを予測します。
よってmake_data関数では返り値がx, yの2つ帰ってきます。xが学習データのリスト、yが結果データのリストです。
次はいよいよsklearnライブラリに入っているLinearRegression(線形回帰)を用いてデータの学習、予測を開始します。
興味深いのは線形回帰という高度な統計手法を数学的な知識を一切使わずに行えることです。
恐るべしライブラリ。ライブラリ使いまくりでも人工知能は人工知能、まさに「ノリとアイデアだけで勝負する」を実現させてくれる強力なツールです。
さて、予測が終わったらグラフに表示させるだけです。結果はこのようになりました。
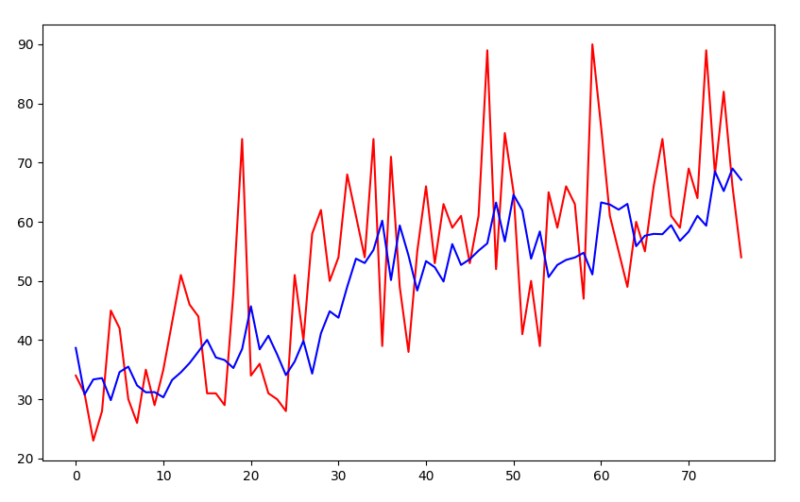
赤が実際のPV、青がAIが予測したPVです。細かいトレンドは追い切れてない感がありますが、大きなサイクルのパターンは掴めているようです。
数値で見てみると、平均誤差が±10PV、最大38PVとなりました。およそ80%の精度です。
今回は14ヶ月分のデータでの試みでしたが、もう少しデータを増やしてクロスバリデーションやグリッドサーチを利用すれば精度がもう少し上がると思います。
まとめ
以上、機械学習でPV予測プログラムの紹介でした。
先述のとおり、実装だけなら人工知能の開発には数学の知識はそれほど必要ありません。
「AI開発に挑戦したいけど数学とかムリ」と尻込みをしている方がいたら、一度sklearnの公式ライブラリや関連書籍を読んで、実際にコードを書いてみることをおすすめしたいです。